Results
We proposed two new metrics that estimate the quality of adversarial attack detectors. The quality of
detectors can also be estimated using a simple test set with both attacks and normal examples. When
using a test set, however, we expected that we are not really measuring the detector's effectiveness
against real-life adversarial attacks, but only its effectiveness against the old attacks in the test
set. In short, we expect that we will get different (more reliable) results when using the two new
metrics compared to when we test using a test set with attacks.
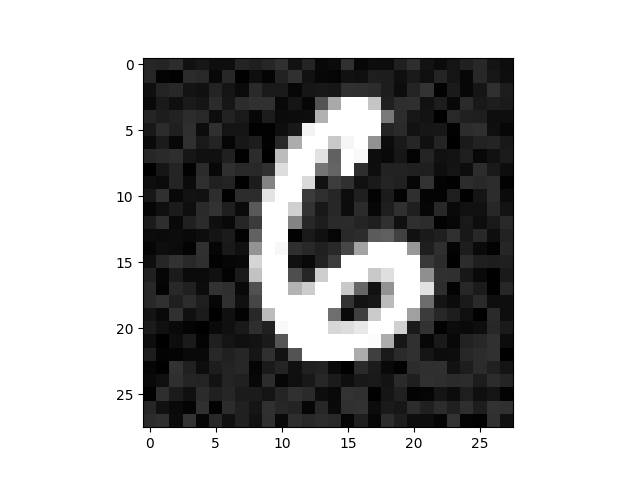
To see if this is indeed the case, we performed experiments with nine different detectors. These detectors
were trained to detect attacks on a neural network that can recognize handwritten digits. Specifically,
the neural network classifies images from the
MNIST dataset. This dataset contains
grayscale pictures of 28 by 28 pixels of handwritten digits.
An adversarial attack
on this network is an image that looks like one number (e.g. 6) that has been deliberately perturbed
such that the network classifies it as a different number (e.g. 4). Therefore, the nine detectors
take images of handwritten digits and judge whether such an image is an adversarial attack.
For each of
these detectors, we evaluated its quality according to both a plain test set, and the two new metrics.
The results are plotted in the graphs below, where each dot represents one detector.
In these graphs, the quality according to the test set is
shown on the X-axis, where the quality increases from right to left; and the quality according to the
new metric is shown on the Y-axis, where the quality increases from top to bottom. The left graph
shows the new metric related to the false negatives on the Y-axis, and the right graph shows the
metric related to the false positives on the Y-axis.
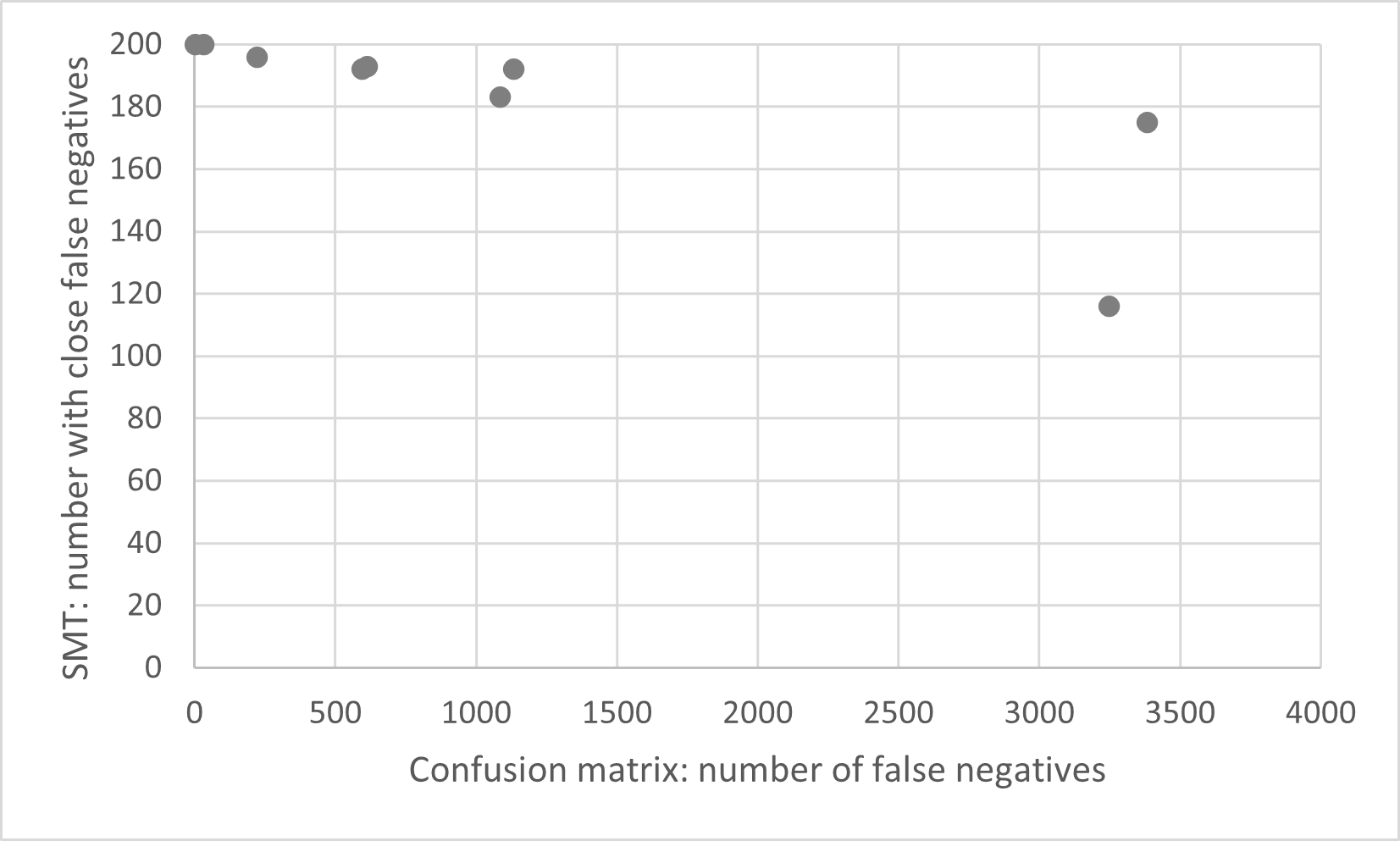
In the left graph, a negative correlation can be observed between the two metrics. This graph shows
the quality with respect to the number of false negatives: that is, the number of images that are
really adversarial, but not flagged as such by the detector. The negative correlation indicates that
as the quality goes up according to the test set, the quality actually goes down according to our new
metric. This is an interesting result. It suggests that the detector is overfitting on the attacks
in the test set. Therefore, it is very good at detecting those old attacks. However, at the same time,
the new metric shows that the detector is not really good at detecting attacks in general.
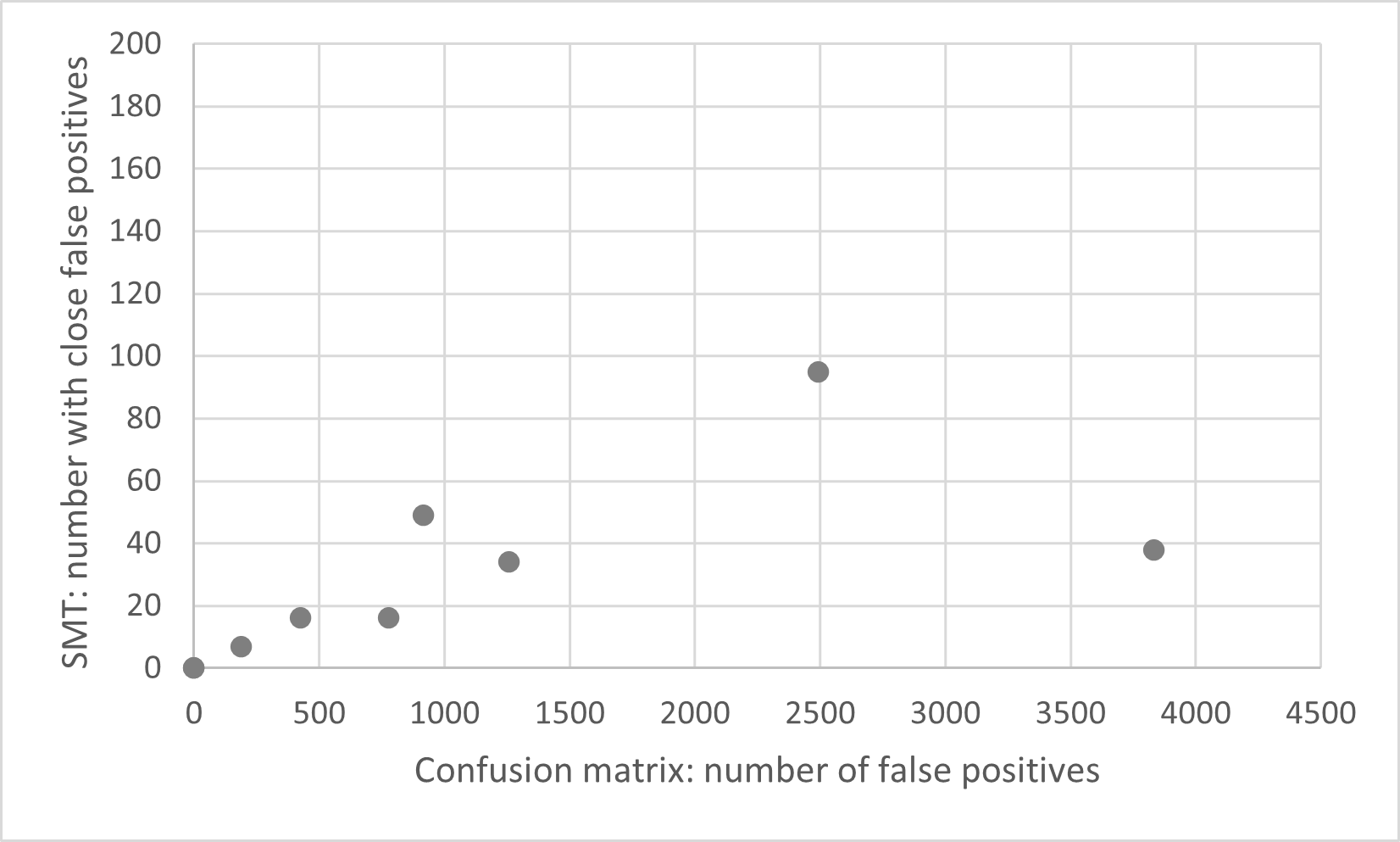
The graph on the right shows the quality with respect to the
number of false negatives: that is, the number of images that are really not adversarial, yet the
detector flags them as adversarial.
This graph shows a positive correlation, which indicates that as the quality goes up according to the
test set, it also goes up according to our new metric.
This indicates that the detectors are not overfitting on normal examples.
We can conclude from these results that our two new metrics are indeed useful when we want to know the
quality of adversarial attack detectors. While it costs a bit of time to answer the questions posed by
the metrics, they do not suffer from the historic bias, which is problematic when we only test using
a test set with old attacks.






